Make-An-Animation
Large-Scale Text-conditional 3D Human Motion Generation (ICCV 2023)
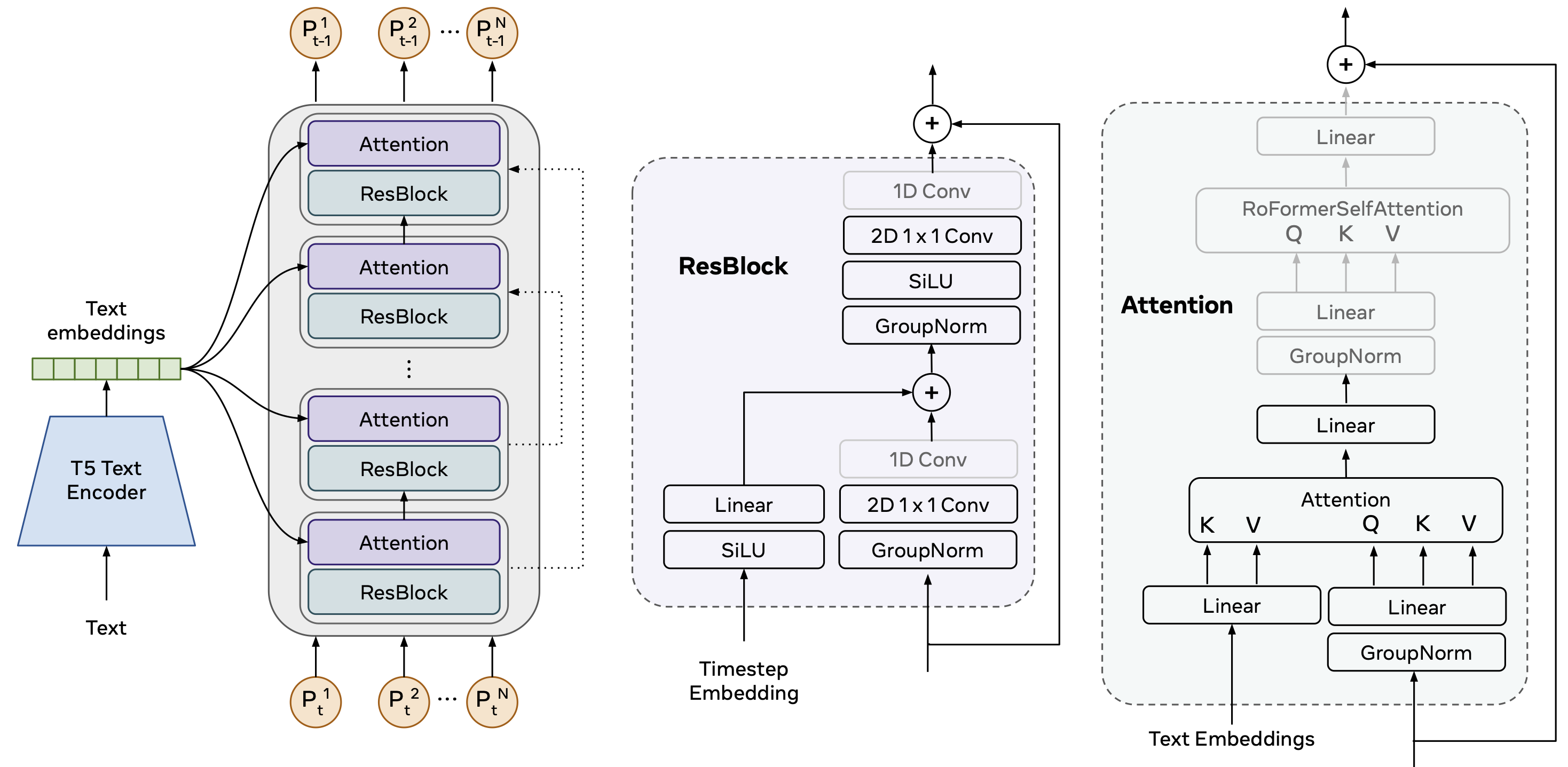
Text-guided human motion generation has drawn significant interest because of its impactful applications spanning animation and robotics. Recently, application of diffusion models for motion generation has enabled improvements in the quality of generated motions. However, existing approaches are limited by their reliance on relatively small scale motion capture data, leading to poor performance on more diverse, in-the-wild prompts. In this paper, we introduce Make-An-Animation (MAA), a text-conditioned human motion generation model which learns more diverse poses and prompts from large-scale image-text datasets, enabling significant improvement in performance over prior works. Make-An-Animation is trained in two stages. First, we train on a curated large-scale dataset of (text, static pseudo-pose) pairs extracted from image-text datasets. Second, we fine-tune on motion capture data, adding additional layers to model the temporal dimension. Unlike prior diffusion models for motion generation, Make-An-Animation uses a U-Net architecture similar to recent text-to-video generation models. Human evaluation of motion realism and alignment with input text shows that our model reaches state-of-the-art performance on text-to-motion generation.
*Samples rendered by an internal rendering engine.



A dog runs by and my avatar pets it.
A person is rowing a small dingy in a river.
A person is stretching their leg.
A photographer is looking through the camera.



A person is chopping down a tree with an axe.
A person gets down on their knee at their favorite spot overlooking the ocean.
A person running and leaping across rooftops.
A person is petting a llama.



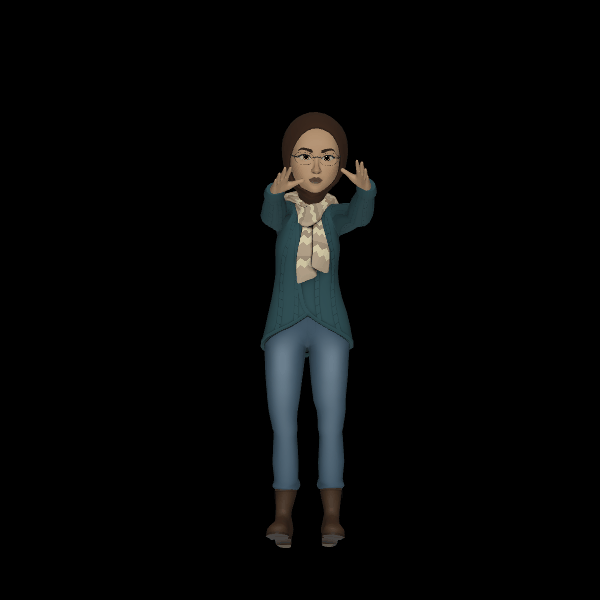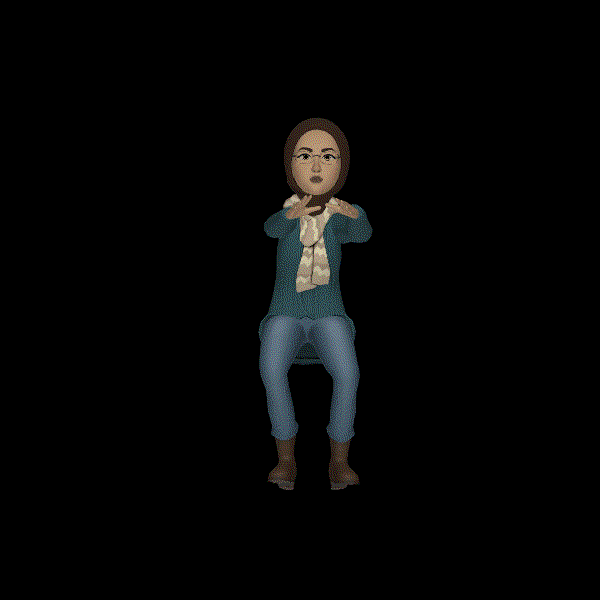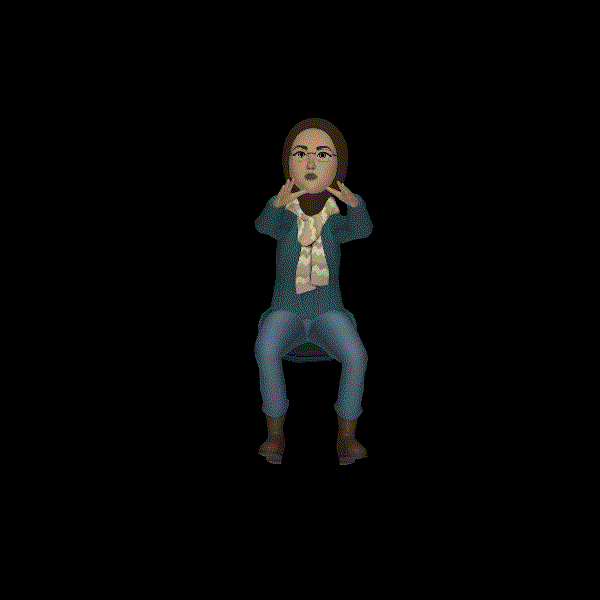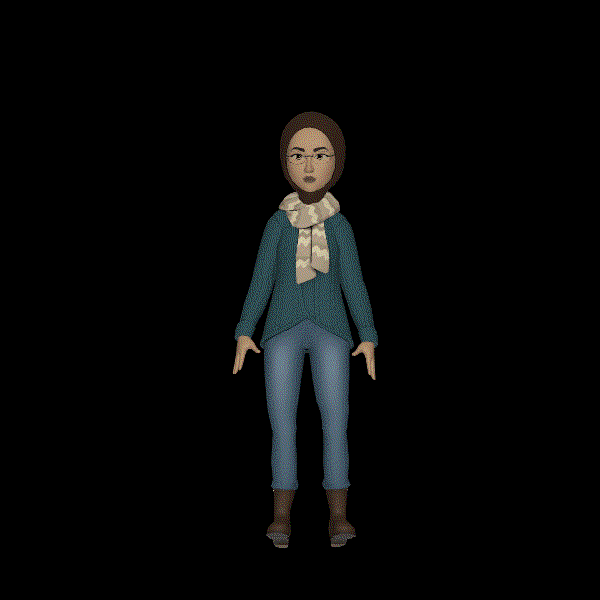
A human excited and celebrating.
A ballerina performs a beautiful and difficult dance on the roof of a very tall skyscraper.
A person dancing in the street.
A person doing squats on top of a bench in the park.



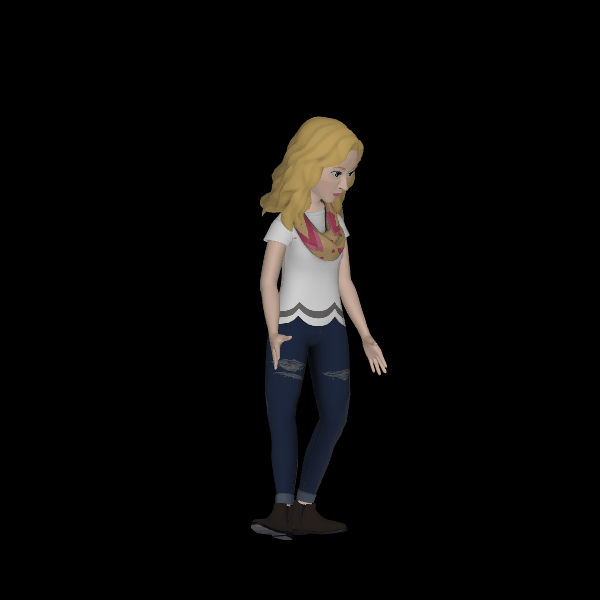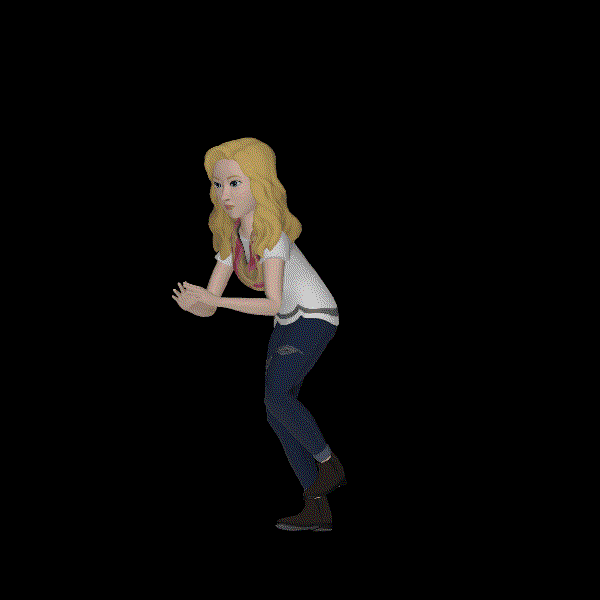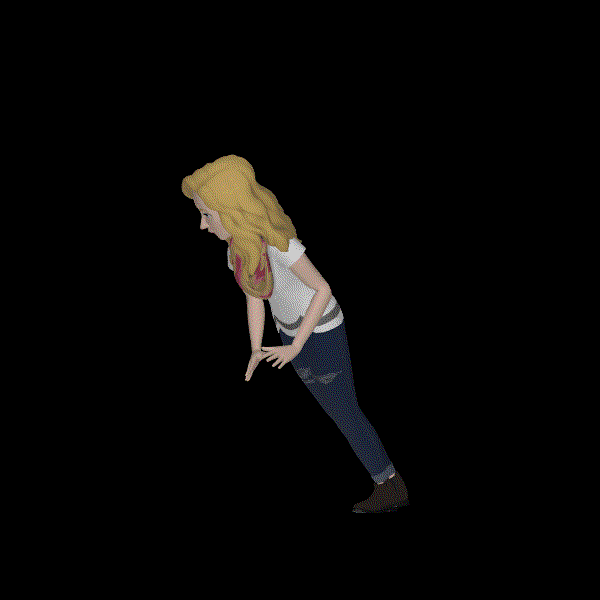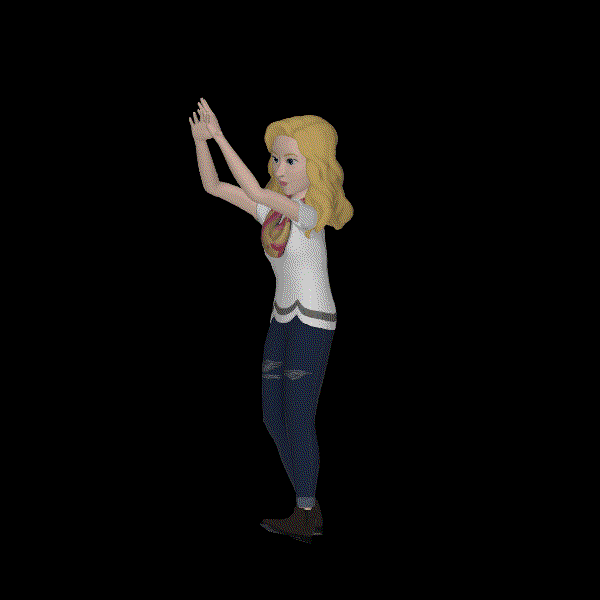
A sad human crying.
A person dancing during a heavy rainstorm.
Me fixing my hair in front of a mirror.
A person climbing a ladder on the side of a building.
MAA
MDM [1]
T2M [2]
A miner is digging for gold with a pickaxe.
A fisher is patiently fishing in a clear blue lake.
A person doing pushups at the gym.
A person extends their hand for a handshake in the classroom.
A person gets down on their knee at their favorite spot overlooking the ocean.
A person is juggling 3 balls.
A person is playing piano at a church.
A person is praying.
A person is sawing a branch off of a tree.
A person is smelling a flower.
A person doing jumping jacks outside on the pavement.
A dog runs by and my avatar pets it.